Hva er tegnkodinger som ANSI og Unicode, og hvordan de forskjellige?
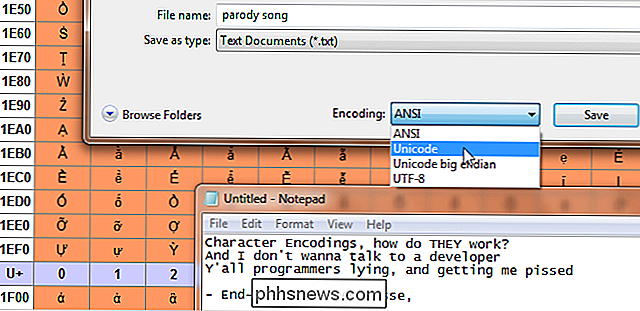
ASCII, UTF-8, ISO-8859 ... Du har kanskje sett disse merkelige monikene flyter rundt, men hva gjør de egentlig mener? Les videre når vi forklarer hvilken tegnkodning er, og hvordan disse akronymer relaterer seg til ren tekst som vi ser på skjermen.
Fundamentelle byggeblokker
Når vi snakker om skriftspråk, snakker vi om bokstaver som er byggeblokkene av ord, som da bygger setninger, avsnitt, og så videre. Bokstaver er symboler som representerer lyder. Når du snakker om språk, snakker du om grupper av lyder som kommer sammen for å danne en slags mening. Hvert språksystem har et komplekst sett med regler og definisjoner som styrer disse betydningen. Hvis du har et ord, er det ubrukelig med mindre du vet hvilket språk det er fra, og du bruker det med andre som snakker språket.

(Sammenligning av Grantha, Tulu og Malayalam-skript, Bilde fra Wikipedia)
I verden av datamaskiner bruker vi begrepet "karakter". Et tegn er et abstrakt konsept, definert av bestemte parametere, men det er den grunnleggende betydningsenheten. Latinen 'A' er ikke den samme som en gresk 'alfa' eller en arabisk 'alif' fordi de har forskjellige sammenhenger - de er fra forskjellige språk og har litt forskjellige pronunciations - slik at vi kan si at de er forskjellige tegn. Den visuelle representasjonen av et tegn kalles en "glyph" og forskjellige sett av glyfer kalles skrifter. Grupper av tegn tilhører et "sett" eller et "repertoar".
Når du skriver opp et avsnitt og du endrer skriften, endrer du ikke fonetiske verdier av bokstavene, du endrer hvordan de ser ut. Det er bare kosmetisk (men ikke ubetydelig!). Noen språk, som gamle egyptiske og kinesiske, har ideogrammer; disse representerer hele ideer i stedet for lyder, og deres uttalelser kan variere over tid og avstand. Hvis du erstatter ett tegn til et annet, erstatter du en ide. Det er mer enn bare å endre bokstaver, det endrer et ideogram.
Tegnkoding

(Bilde fra Wikipedia)
Når du skriver noe på tastaturet, eller laster en fil, vet hvordan datamaskinen skal vise? Det er hva tegnkodingen er for. Tekst på datamaskinen er egentlig ikke bokstaver, det er en serie parede alfanumeriske verdier. Tegnkodingen fungerer som en nøkkel for hvilke verdier som samsvarer med hvilke tegn, omtrent som hvordan ortografi dikterer hvilke lyder som tilsvarer hvilke bokstaver. Morse-koden er en slags tegnkoding. Det forklarer hvordan grupper av lange og korte enheter som pip representerer tegn. I Morse-koden er tegnene bare engelske bokstaver, tall og fullstopp. Det er mange datakarakterer som oversetter til bokstaver, tall, aksentkarakterer, tegnsettingstegn, internasjonale symboler og så videre.
Ofte på dette emnet brukes begrepet "kodesider" også. De er i hovedsak tegnkodninger som brukes av bestemte selskaper, ofte med små endringer. For eksempel er Windows 1252-kodesiden (tidligere kjent som ANSI 1252) en modifisert form av ISO-8859-1. De brukes hovedsakelig som et internt system for å referere til standard og endrede tegnkodinger som er spesifikke for de samme systemene. I begynnelsen var karakterkoding ikke så viktig fordi datamaskiner ikke kommuniserte med hverandre. Med internett økende til fremtredende og nettverk som en vanlig forekomst, har det blitt en stadig viktigere av våre daglige liv uten at vi selv innser det.
Mange forskjellige typer
(Bilde fra sarah sosiak)
Det er mange forskjellige tegnkodinger der ute, og det er mange grunner til det. Hvilken tegnkodning du velger å bruke, avhenger av hva dine behov er. Hvis du kommuniserer på russisk, er det fornuftig å bruke en tegnkodning som støtter cyrillisk brønn. Hvis du kommuniserer på koreansk, vil du ha noe som representerer Hangul og Hanja godt. Hvis du er matematiker, vil du ha noe som har alle de vitenskapelige og matematiske symbolene representert godt, så vel som de greske og latinske glyphs. Hvis du er en prankster, kan du kanskje dra nytte av opp-ned-tekst. Og hvis du vil at alle disse typer dokumenter skal sees av en bestemt person, vil du ha en koding som er ganske vanlig og lett tilgjengelig.
La oss ta en titt på noen av de vanligste.

(Utdrag av ASCII-tabellen, Bilde fra asciitable.com)
- ASCII - Den amerikanske standardkoden for informasjonsutveksling er en av de eldre tegnkodningene. Den ble opprinnelig utarbeidet basert på telegrafiske koder og utviklet seg over tid for å inkludere flere symboler og noen nå utdaterte, ikke-trykte kontrolltegn. Det er sannsynligvis så grunnleggende som du kan få når det gjelder moderne systemer, da det er begrenset til det latinske alfabetet uten aksenterte tegn. Dens 7-biters koding tillater bare 128 tegn, derfor finnes det flere uoffisielle varianter i bruk over hele verden.
- ISO-8859 - Den internasjonale organisasjonen for standardiseringens mest brukte gruppe av tegnkodinger er nummer 8859 . Hver spesifikk koding er betegnet med et tall, ofte prefikset av en beskrivende moniker, f.eks ISO-8859-3 (Latin-3), ISO-8859-6 (Latin / Arabisk). Det er en superset av ASCII, noe som betyr at de første 128 verdiene i kodingen er de samme som ASCII. Det er imidlertid 8-bit, og tillater 256 tegn, så det bygger seg derfra, og inneholder et mye bredere utvalg av tegn, med hver bestemt koding som fokuserer på et annet sett av kriterier. Latin-1 inkluderte en rekke aksentiserte bokstaver og symboler, men ble senere erstattet med et revidert sett som heter Latin-9, som inneholder oppdaterte glyfer som eurosymbolet.
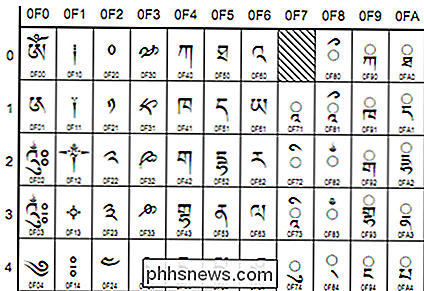
(Utdrag av tibetansk skript, Unicode v4, fra unicode.org)
- Unicode - Denne kodingsstandarden tar sikte på universalitet. Den inneholder for øyeblikket 93 skript som er organisert i flere blokker, med mange flere i verkene. Unicode virker annerledes enn andre tegnsett i at i stedet for direkte koding for en glyph, blir hver verdi rettet videre til et "kodepunkt". Dette er heksadesimale verdier som tilsvarer tegn, men glyphene selv er gitt i frittstående måte av programmet , for eksempel nettleseren din. Disse kodepunktene er vanligvis vist som følger: U + 0040 (som oversetter til '@'). Spesifikke kodinger under Unicode-standarden er UTF-8 og UTF-16. UTF-8 forsøker å tillate maksimal kompatibilitet med ASCII. Det er 8-bit, men tillater alle tegnene via en substitusjonsmekanisme og flere par verdier per tegn. UTF-16 gir deg perfekt ASCII-kompatibilitet for en mer komplett 16-biters kompatibilitet med standarden.
- ISO-10646 - Dette er ikke en faktisk koding, bare et tegnsett Unicode som er standardisert av ISO. Det er mest viktig fordi det er karakterrepertoaret som brukes av HTML. Noen av de mer avanserte funksjonene som tilbys av Unicode som tillater samling og høyre til venstre sammen med venstre til høyre skripting mangler. Likevel fungerer det veldig bra for bruk på internett, da det tillater bruk av et bredt spekter av skript og lar nettleseren tolke glyphene. Dette gjør lokalisering litt enklere.
Hvilken koding skal jeg bruke?
Vel, ASCII fungerer for de fleste engelsktalende, men ikke for mye annet. Oftere ser du ISO-8859-1, som fungerer for de fleste vesteuropeiske språk. De andre versjonene av ISO-8859 virker for kyrillisk, arabisk, gresk eller andre spesifikke skript. Men hvis du vil vise flere skript i samme dokument eller på samme nettside, gir UTF-8 mye bedre kompatibilitet. Det fungerer også veldig bra for folk som bruker ordentlig tegnsetting, matte symboler eller karakterer utenfor bokstaver, for eksempel kvadrater og boksene.

(Flere språk i ett dokument, Skjermbilde av gujaratsamachar.com)
Det er ulempene til hvert sett, imidlertid. ASCII er begrenset i tegnsetting, så det virker ikke så bra for typografisk korrekte redigeringer. Har du noen gang skrevet kopi / lim inn fra Word bare for å ha litt merkelig kombinasjon av glyphs? Det er ulempen med ISO-8859, eller mer korrekt, det antas at den kan opereres med OS-spesifikke kodesider (vi ser på deg, Microsoft!). UTF-8s store ulempe er mangel på riktig støtte i redigering og publisering av applikasjoner. Et annet problem er at nettlesere ofte ikke tolker og bare viser byteordremerket til et UTF-8-kodet tegn. Dette resulterer i at uønskede glyfer vises. Og selvfølgelig er det vanskelig for nettleserne å gjengi dem riktig og for søkemotorer å indeksere dem på riktig måte, selv om de som erklærer en koding og bruk av tegn fra en annen uten å erklære / referere dem riktig på en nettside, er det selvsagt vanskelig.
For dine egne dokumenter, manuskripter og så videre, kan du bruke alt du trenger for å få jobben gjort. Så langt som nettet går, ser det ut til at de fleste er enige om å bruke en UTF-8-versjon som ikke bruker et byteordre, men det er ikke helt enstemmig. Som du kan se har hver tegnkoding egen bruk, kontekst og sterke og svake sider. Som sluttbruker trenger du sannsynligvis ikke å håndtere dette, men nå kan du ta det ekstra fremover hvis du velger det.

Slik beskytter du datamaskinen mot hackere, spionprogrammer og virus
Denne artikkelen har blitt inspirert av en situasjon jeg kjørte inn i mens jeg besøkte en fetter i India. Siden jeg er i IT-feltet, spurte hun meg om å se på datamaskinen hennes siden det virket "morsomt". Den "morsomme" delen var at datamaskinen automatisk ville starte igjen når du prøvde å installere noe programvare på det eller laste ned et hvilket som helst program fra Internett.Det før
Begynnerveiledning til Windows Command Prompt
Tidligere i dag måtte jeg starte en klientdatamaskin i sikker modus og slette et virus via kommandoprompten, for når Windows ville laste, ville filen bli låst og dermed utelukkelig! Det er flere andre grunner til at du kanskje må bruke kommandoprompten i livet ditt (men sjelden), så det er godt å vite hvordan du skal navigere deg rundt!Hvis